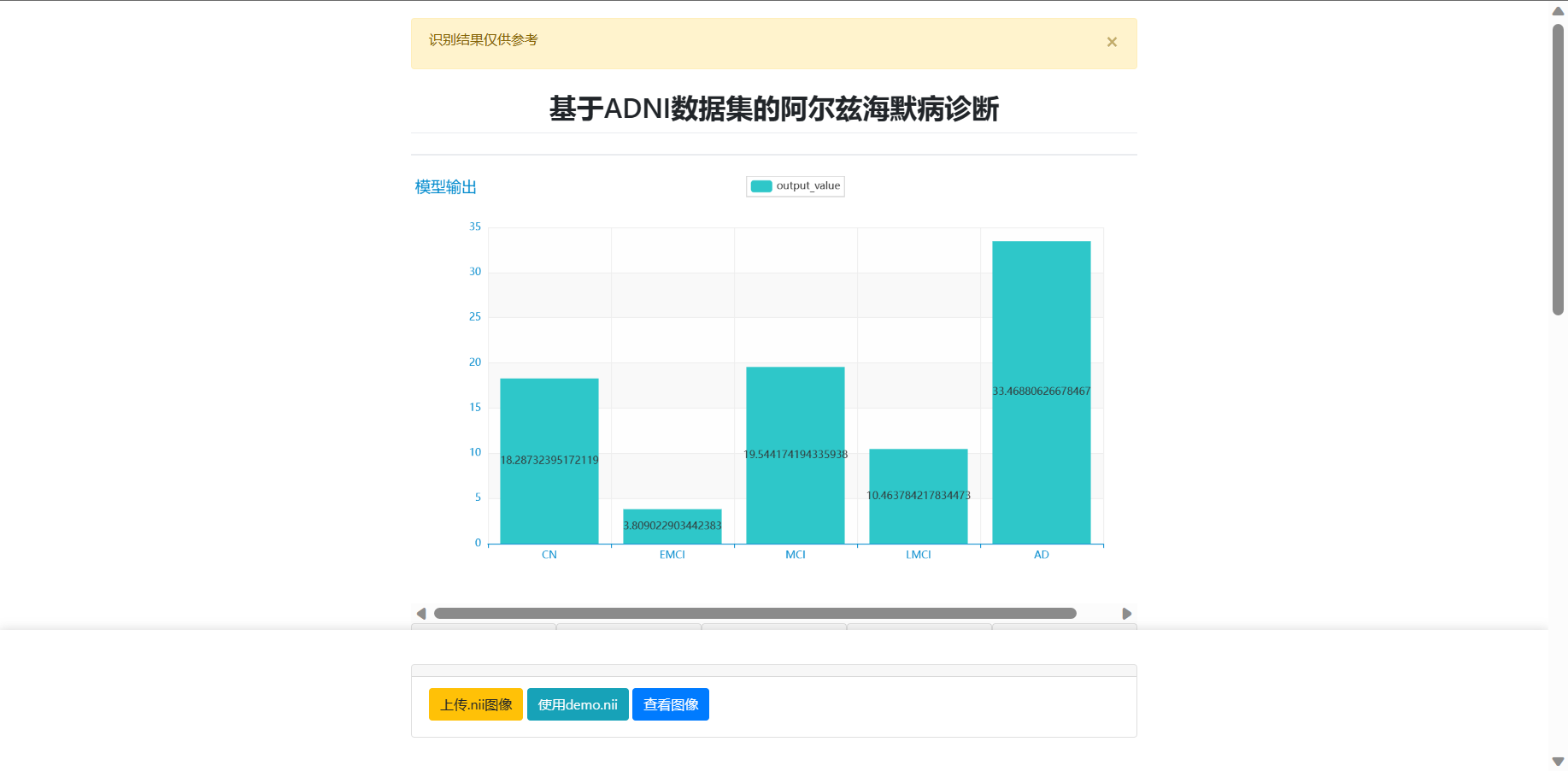
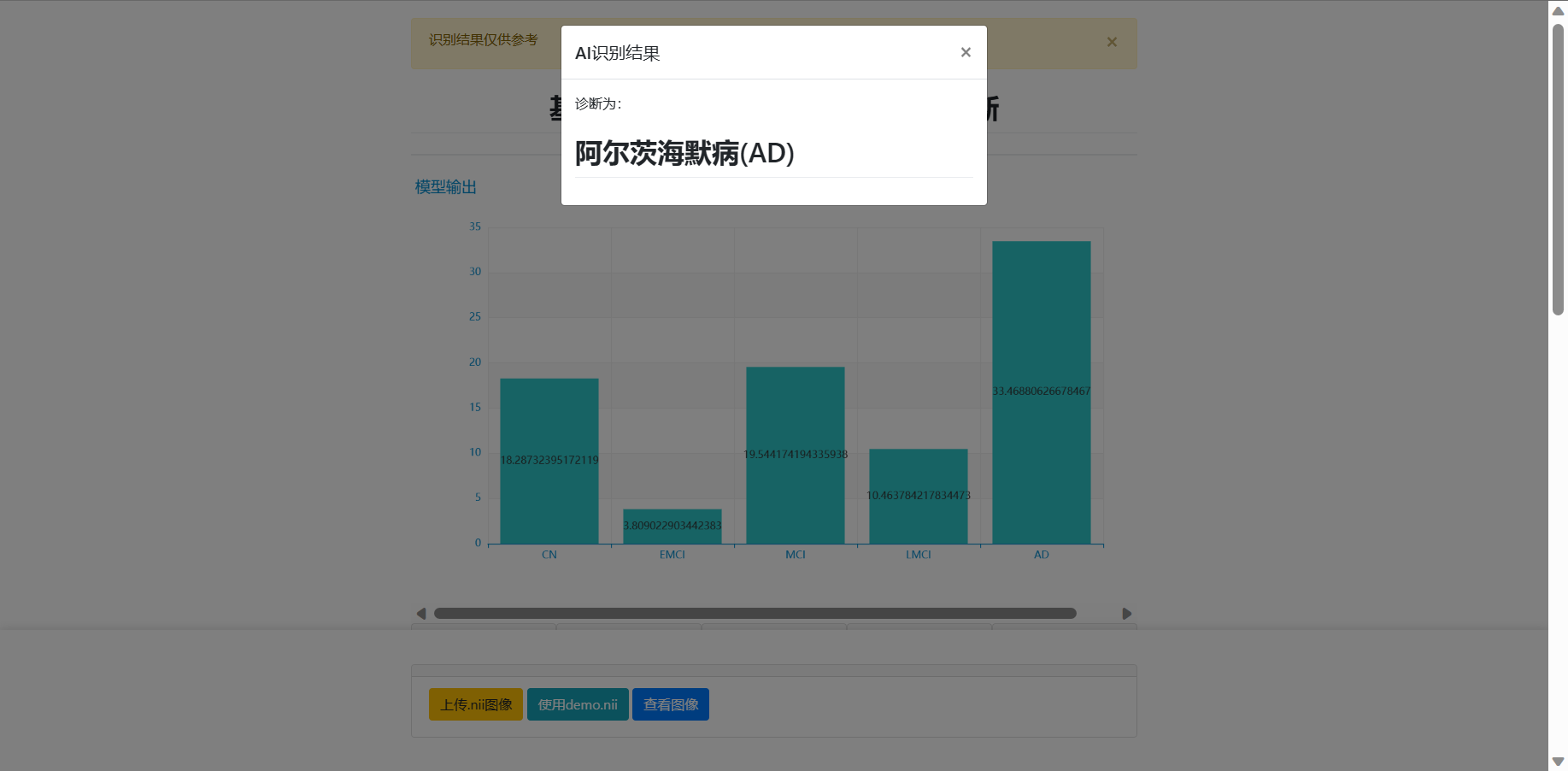
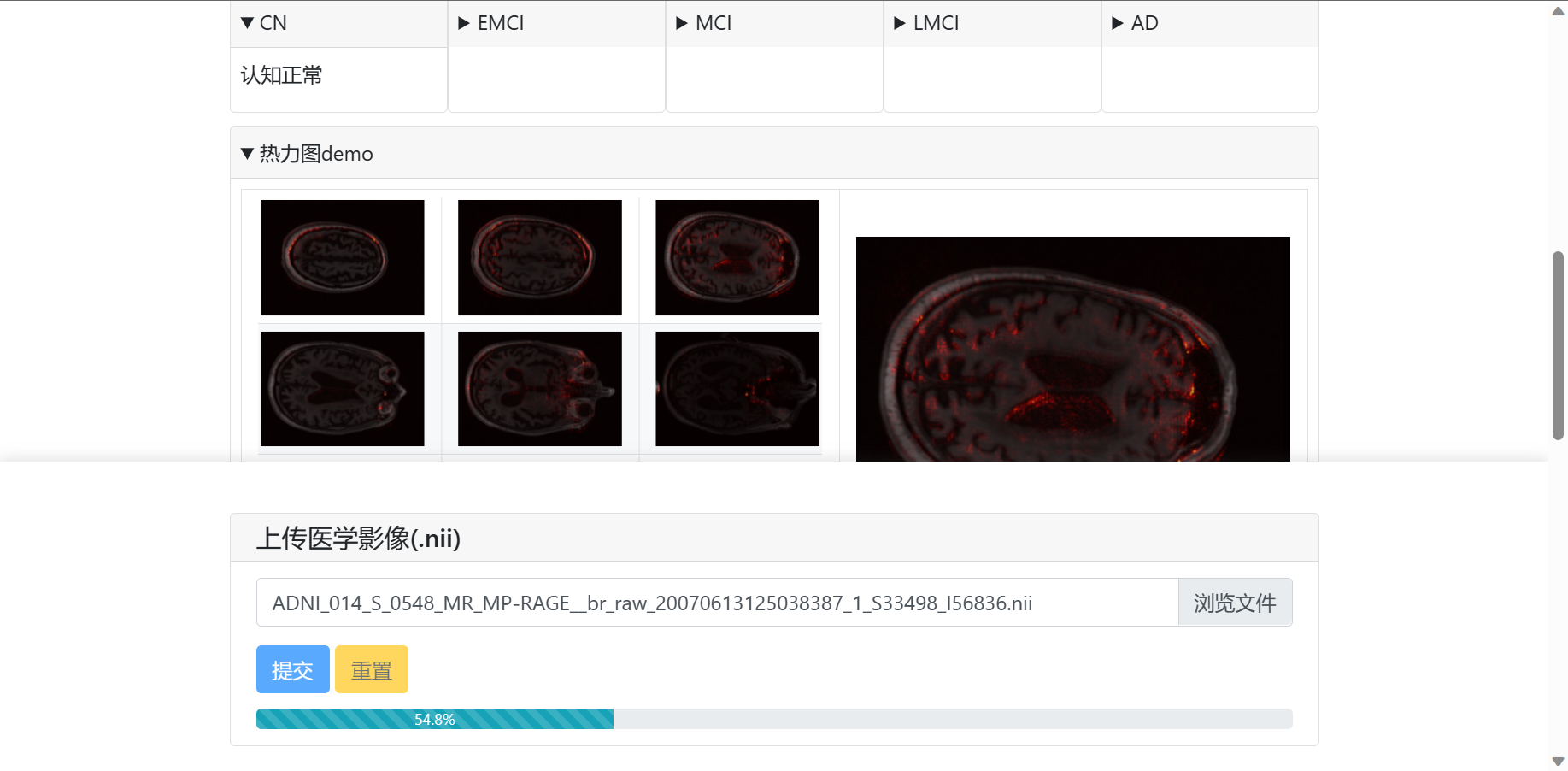
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
| from torch import nn
import torch
class ClassificationModel3D(nn.Module):
"""分类器模型"""
def __init__(self, dropout=0.4, dropout2=0.4):
nn.Module.__init__(self)
self.Conv_1 = nn.Conv3d(1, 8, 3)
self.Conv_2 = nn.Conv3d(8, 16, 3)
self.Conv_3 = nn.Conv3d(16, 32, 3)
self.Conv_4 = nn.Conv3d(32, 64, 3)
self.Conv_1_bn = nn.BatchNorm3d(8)
self.Conv_2_bn = nn.BatchNorm3d(16)
self.Conv_3_bn = nn.BatchNorm3d(32)
self.Conv_4_bn = nn.BatchNorm3d(64)
self.Conv_1_mp = nn.MaxPool3d(2)
self.Conv_2_mp = nn.MaxPool3d(3)
self.Conv_3_mp = nn.MaxPool3d(2)
self.Conv_4_mp = nn.MaxPool3d(3)
self.dense_1 = nn.Linear(4800, 128)
self.dense_2 = nn.Linear(128, 5)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout2)
def forward(self, x):
x = self.relu(self.Conv_1_bn(self.Conv_1(x)))
"""
这行代码是对输入 x 进行卷积、批归一化和 ReLU 激活函数的操作。
self.Conv_1(x) 对输入 x 进行 3D 卷积操作,输出一个特征图。
self.Conv_1_bn(...) 对卷积输出的特征图进行批归一化操作,得到归一化后的特征图。
self.relu(...) 对归一化的特征图进行 ReLU 激活函数操作,得到激活后的特征图。
整个操作的作用是提取输入 x 中的特征,并将其非线性化,使得网络能够更好地学习这些特征。这里使用了批归一化的技术,可以加速模型的训练过程并提高模型的泛化能力。最终得到的输出结果是经过卷积、批归一化和 ReLU 激活函数处理后的特征图 x。
"""
x = self.Conv_1_mp(x)
"""
这行代码是对输入 x 进行最大池化操作,将特征图的大小缩小一半。
self.Conv_1_mp(...) 对输入 x 进行最大池化操作,池化核大小为 2。
池化操作会将特征图中每个池化窗口内的最大值提取出来,作为输出特征图的对应位置的值,从而将特征图的大小缩小一半。
最大池化操作可以帮助网络实现空间不变性,使得网络在输入发生轻微变化时仍能识别出相同的特征。在这个模型中,经过最大池化后的特征图 x 会传递到下一层卷积层中进行特征提取和非线性化处理。
"""
x = self.relu(self.Conv_2_bn(self.Conv_2(x)))
x = self.Conv_2_mp(x)
x = self.relu(self.Conv_3_bn(self.Conv_3(x)))
x = self.Conv_3_mp(x)
x = self.relu(self.Conv_4_bn(self.Conv_4(x)))
x = self.Conv_4_mp(x)
x = x.view(x.size(0), -1)
"""
这行代码是将输入张量 x 展平为一维向量。
x.size(0) 得到输入张量 x 的第一个维度的大小,也就是张量的批次大小。
-1 表示将第二个维度及其后面的所有维度展平为一维。
x.view(...) 对输入张量 x 进行形状变换,将其展平为一维向量。
这个操作的作用是将经过卷积和池化处理后的特征图 x 变为一维向量,以便于传递到全连接层进行分类或回归等任务。展平后的向量大小为 (batch_size, num_features),其中 batch_size 是输入张量的批次大小,num_features 是展平后的向量元素个数,也就是经过卷积和池化处理后的特征数量。
"""
x = self.dropout(x)
"""
这行代码是对输入张量 x 进行 dropout 操作,即以一定概率将输入张量中的部分元素置为零。
self.dropout(...) 对输入张量 x 进行 dropout 操作,丢弃概率为 dropout。
dropout 操作会以一定概率将输入张量中的部分元素置为零,从而达到随机失活的目的。这样做可以减少过拟合,增强模型的泛化能力。
在这个模型中,dropout 操作被应用在全连接层之前,可以帮助模型更好地学习到数据的特征,防止过拟合。最终得到的 x 张量是经过 dropout 操作后的结果,会传递到下一层全连接层进行处理。
"""
x = self.relu(self.dense_1(x))
"""
这行代码是对输入张量 x 进行全连接操作,并应用 ReLU 激活函数。
self.dense_1(x) 对输入张量 x 进行全连接操作,将其映射到大小为 128 的特征空间中。
self.relu(...) 对全连接层的输出进行 ReLU 激活函数操作,得到激活后的特征向量。
在这个模型中,全连接层的作用是将经过卷积、池化和 dropout 处理后的特征向量映射到一个新的特征空间中,以便于进行分类或回归等任务。ReLU 激活函数的作用是对特征向量进行非线性化处理,使得网络能够更好地学习到数据中的非线性相关性。最终得到的 x 张量是经过全连接层和 ReLU 激活函数处理后的结果,会传递到下一层 dropout 层进行处理。
"""
x = self.dropout2(x)
x = self.dense_2(x)
return x
if __name__ == "__main__":
model = ClassificationModel3D()
test_tensor = torch.ones(1, 1, 166, 256, 256)
output = model(test_tensor)
print(output.shape)
|